第10回 PDFのデータ活用 ― Word、Excel へ変換の問題点と対処法 ―
WordやExcelに上手に変換できないPDF
前回はPDFをWordやExcelへの変換をご紹介しました。様々なPDFをWordやExcelに変換していると、中には期待したような文書に変換できなかったり、変換自体ができないPDFがあることに気付かれると思います。
見た目ではわかりにくいのですが、PDFは同じレイアウトの文書でも原理上はいろいろな作り方が可能です。人間にとっては同じに見えたとしても、コンピュータには異なって見える場合があり、変換後のWordやExcelファイルが期待した結果にならないことがあります。
今回はその中から3つの事例と対処法をご紹介します。

文字が図形の集合でできたPDF
ここでご紹介するPDFは、一見するととてもきれいなPDFで、画面を拡大しても文字がぼやけたり滲むことなく、印刷も問題なくできます。
ところが、PDFの文字部分が選択できず、文字をコピーすることができません。また、Acrobat ReaderでこのPDFのプロパティを見ると、「フォント」が空欄でPDFにでは文字にフォントが使われていないことがわかります。
実はこのPDF、文字の部分がすべて線画(ベクトル図形)になっているため、前述のように文字として選択することができないのです。このようなPDFはアウトラインPDFとも呼ばれ、デザインや印刷の業界でよく利用されていました。
文字の部分がすべて線画なので、人間は見た瞬間それが文字であると認識できるのに、コンピュータは文字として認識ができません。

こうしたPDFをWordやExcelに変換するには、ページ全体をピクセル画像に変換し、その画像をOCR処理します。
文字や図形の一部が「注釈」で作られたPDF
次に紹介するPDFは、WordやExcelに変換すると一部の文字や図形が消えてしまう現象のPDFをご紹介します。
いろいろな原因が考えられますが、よくあるのは、文字の一部や図形がPDFの注釈データで追記されていて、その部分が欠落してしまうというものです。
今ではOS自体がPDFの生成や表示をサポートしています。EdgeやChromeといったWebブラウザはもちろん、スマートフォンのような携帯端末でもPDFを表示することができるようになりました。こうしたPDFを表示できるソフトウェアの多くは、文字や図形、手書きの線などをPDFへ「追記」できる機能も持っています。
しかし、あまり知られていませんが、追記された文字や図形は実は注釈データなのです。無料(フリー)のPDF表示ソフトウェアの多くが注釈データの表示や追記に対応していますが、PDFをWordやExcelに変換するソフトウェアの一部ではいまだに注釈データに対応していないものがあります。
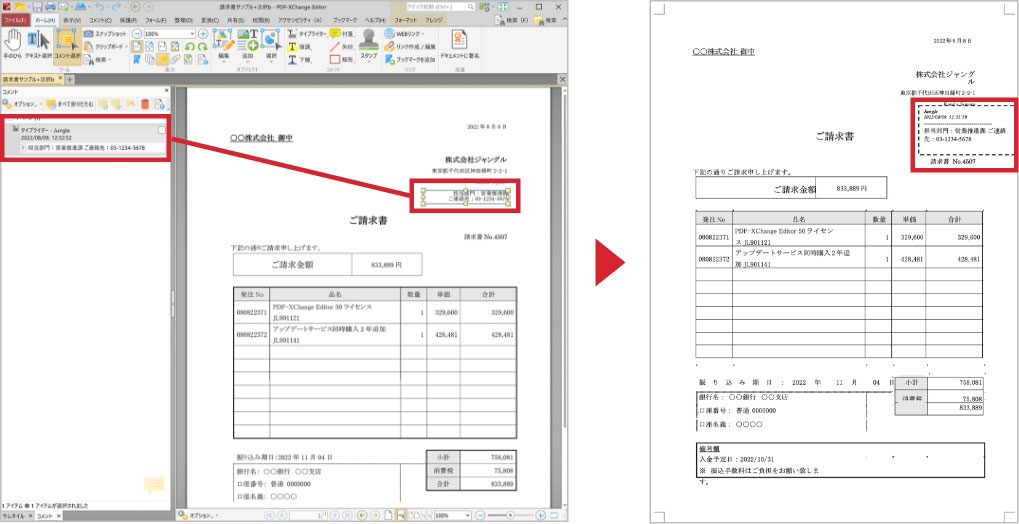

こうしたPDFをWordやExcelに変換するには、ページ全体をピクセル画像に変換し、その画像をOCR処理します。または、注釈に対応した変換ソフトウェアを利用します。
試しにPDF-XChange EditorでWordに変換すると、注釈データをできるだけ忠実に Wordで再現してくれます。この辺りはまさに面目躍如といった感じで、ソフトウェアベンダーの力量の差が表れているといえるでしょう。
隠れた文字がある
次のようなPDFでは、WordやExcelに変換すると実際の文字と画面や印刷で認識できる文字とが一致しないことがあります。

画像の後ろや紙面サイズから
離れた位置に配置されているケース

見えないくらい小さい文字が
配置されているケース

白や透明なテキストが
配置されているケース
こうしたPDFは、PDFが持つテキスト(文字を選択してコピーしたテキスト)と、画面や印刷したものなど人間が目で読み取れるテキストとが異なってしまいます。前2例のようにPDFを画像化してOCR処理をしても解決しません。
今のところありません。見た目通りでよければそのままPDFを画像化してOCR処理します。隠れたテキストを抽出するには、PDF全体を選択してテキストをコピーします。
迷ったらOCRを使った変換がおススメ
代表的な3つの事例を紹介しましたが、これ以外にも様々なケースが存在します。ほとんどの場合、見た目をそのままWordやExcelで再現できればよいので、OCR処理で切り抜けるのがよいでしょう。
OCRによる100%の文字認識は厳しいため、PDFからWordやExcelへの変換精度はまだまだ低いと考える方も多いと思います。PDFならではの事情で難しい面もありますが、AIを使った変換など今後の進化に期待したいものです。
